Recent Posts
ZFS Inode Generations
Quickly determining the ZFS transaction generation of an inode.
I recently had reason to write a tool to replay some of the ZFS snapshot history of a server. I wanted to merge two old volumes into three new volumes in order to have their snapshot retainment schedules better match their content. The bulk of that is a story for another time.
To be efficient, the tool needed to be able to track files as they were changed through snapsnots and "replay" those changes. An early idea was to match up inodes (and e.g. compare ctimes, etc.), but as I started testing the tool I noticed that there were occasionally inode pairs that did not make sense; files in one snapshot had the same inode as directories in a later one.
Only then did it click that inodes are recycled, and matching inodes alone was not enough.
Sudo-less TLS with Let's Encrypt
`acme.sh` brings a straighforward setup.

I've been using Let's Encrypt since they opened to the public for every site I control.
I was not happy with Certbot because of the complexity in getting it to work without root access (which I really don't want to hand out to everything that asks for it, even if they are trustworthy). Out of the box, Certbox seemed easy and automatic. If you didn't want to use it in exactly that way... less so.
This is actually my 3rd attempt at writing a blog post of my Let's Encrypt setup, as I was never happy with the bulk I ended up with. Now that we have acme.sh, lets try again!
A Bondmode Band-Aid
In which an ever-ready watch keep standing up the bond when it spontaneously falls down.
WARNING (2017-04-06): I've recently found that something in this setup is corrupting NFS traffic between my machines. I'm going to try to isolate it at some point, but be wary.
I've recently built a personal file server (running Ubuntu 16.04), and elected to try connecting it to my main workstation (a macpro6,1 running macOS Sierra) with a pair of bonded 1Gb/s Ethernet links.

Using the default settings does work, however I don't seem to have any control over how the link is negotiated with LACP. It results in using one of the packet hashing modes that puts entire TCP connections on one link or the other. This seems great for stability, and aggregate throughput, however my use case has be mounting the server via NFS or SMB (which runs via a single connection).
In that case, I'm not getting much benefit out of the bond for my primary use case of setting up the bond at all!
Early on, I discovered that if I set both sides of the bond to be "static", then they would both default into a round-robin style packet distribution. In this mode, I can hit 220-230MB/s while doing file operations!
The problem: macOS spontaneously reverts the bond mode back to LACP.
PxrLMLayer Blending is Broken
Layers only care about themselves.
NOTE: This problem has been fixed by Pixar and released in RenderMan 20.7. It was a interesting bug, so read on anyways!
While working on Shadows in the Grass I've been exploring building RenderMan shaders out of multiple PxrLMLayers. I've been having issues composing shaders of multiple translucent layers.
I've reduced it to a very simple case:

Example 1 (top stripe): I have a base diffuse material with an overlay. The base material is black, and the overlay is red with a gradient mask. Looks like I would expect.
Example 2 (middle stripe): I have a base diffuse material, and two overlays on top. The base material is black, the first overlay is green with a mask of 0, and the second overlay is red with a gradient mask.
I would expect the middle stripe to appear like the top stripe, but the green is somehow getting into the calculation despite its mask being zero.
A Complete Shotgun Schema
Reading the "private" schema for all the details.
My site-local Shotgun cache is coming together quite nicely; you can see the progress on GitHub, as well as the ongoing results of my reverse-engineering efforts.
As work progresses, there is a greater and greater need for a through understanding of Shotgun's database schema so that I can replicate its behavior. One example that I'm starting to tackle: when you query an entity or multi_entity field, the entities will return the (required) type and id, but also a name, however, if you query for that name field you will find that it doesn't actually exist:
>>> # Lets grab the pipeline step of any task: >>> sg.find_one('Task', [], ['step']) {'step': {'type': 'Step', 'id': 4, 'name': 'Matchmove'}, 'type': 'Task', 'id': 2} >>> # Notice the name... ^^^^^^ here. >>> # Let's grab that name directly: >>> sg.find_one('Step', [('id', 'is', 4)], ['name', 'code']) {'code': 'Matchmove', 'type': 'Step', 'id': 4} >>> # No 'name' to be found. Huh.
Another example is the description of back-references of many multi_entity fields. E.g. if you set Task.entity to a Shot, that task will end up in Shot.tasks as well.
I have reached out to Shotgun support, and they have confirmed to me that the schema returned by the public API's schema_read (and related) methods would need to be expanded to return the information I need.
There must be another way to get this information, because the Shotgun website works, and it must have it. So lets go digging there...
Querying Private Shotgun Entities
Deep linking your way into the internal API.
I have been working on a site-local Shotgun cache in order to (1) eliminate the round-trip time to Shotgun's servers, and (2) allow for more expressive queries. This cache primarily operates as an API proxy; it satisfies any requests it can, but if it is missing anything it will forward the request to the real server, and cache the results for next time.
Schema changes are a major concern of mine. Instead of trying to perfectly anticipate how Shotgun will internally mutate data during a schema change, I have opted to simply discard any data affected by such a change.
This still requires me to be able to watch for these changes. My first thought was to watch the event log (by polling for new EventLogEntry entities), and this does show us a schema change, e.g. here is the entry for changing a field's type from "text" to "number":
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | { 'type': 'EventLogEntry', 'id': 1996928, 'event_type': 'Shotgun_DisplayColumn_Change', 'attribute_name': 'data_type', 'entity': {'id': 2836, 'name': 'sg_text_field_1', 'type': 'DisplayColumn'}, 'meta': { 'attribute_name': 'data_type', 'entity_id': 2836, 'entity_type': 'DisplayColumn', 'field_data_type': 'text', 'new_value': 'number', 'old_value': 'text', 'type': 'attribute_change' }, 'user': {'id': 108, 'name': 'Mike Boers', 'type': 'HumanUser'} } |
The problem is that this doesn't mention anywhere what entity type this field is on! Where is CustomEntitity02 in all of this?
"It's okay, Mike", you might say. "You can just query the DisplayColumn entity!". Lets try:
1 2 3 4 5 6 7 8 9 10 | >>> sg.find_one('DisplayColumn', [('id', 'is', 2836)]) Traceback (most recent call last): ... shotgun_api3.shotgun.Fault: API read() invalid/missing string entity 'type': Valid entity types: ["ActionMenuItem", "ApiUser", "AppWelcomeUserConnection", "Asset", ... |
It turns out that DisplayColumn, along with PageSetting (and potentially more entity types) are considered private, and cannot be queried via the standard API.
So... how can we get that data?
A Pop-Up Says "You must update $PLUGIN"
It is okay to respond to these sorts of prompts, and here is why.
There are a few people who I provide tech support to who are becoming increasingly vigilant when it comes to potential phishing attacks. They have been told to "never click links in emails" or "ignore popups that want you to install software". But these are only half truths.
It is completely fine for an email, a phone call, or even a random pop-up to drive you to action. Your bank emails to say you need to change your password? A video site throws a pop-up that you need to update Flash to use it?
These are safe to respond to, but you MUST be the one who initiates the actual actions you have been requested to take, and without the assistance of whatever it was that prompted you to do so.
Static Libraries in a Dynamic World
Creating more honest versions of wrapped APIs.
There is a common pattern when using bindings for C libraries that work against the dynamic language I'm working in: the conceptual packages in the library (which are exposed as header includes, and so provide no extra overhead to use in your code) are actually packages in the binding.
Unless they are flying in the face of good practices, the dynamic language user actually has to work harder to identify a specific function/variable than the static language user would!
The Problem
Let's look at an example Qt program written in C++:
1 2 3 4 5 6 7 8 9 | #include <QApplication> #include <QPushButton> int main(int argc, char *argv[]) { QApplication app(argc, argv); QPushButton hello("Hello world!"); hello.show(); return app.exec(); } |
If we translate directly to Python, we are left with code that feels not only too specific, but puts more of a burden on the programmer than they would have with the static version of the library since they need to know exactly where every object comes from:
1 2 3 4 5 6 7 | import sys from PyQt4 import QtGui app = QtGui.QApplication(sys.argv) hello = QtGui.QPushButton("Hello world!") hello.show() exit(app.exec_()) |
This is something I encounter all the time. For example, in PyQt/PySide, the Adobe Photoshop Lightroom SDK, PyOpenGL, Autodesk's Maya "OpenMaya", PyObjC use of Apple's APIs, etc..
WordPress, and the Pingback of Death
The journey to discover why I couldn't keep a website up.
I host a number of websites for clients, friends, and family. A solid number of those are running WordPress.
I rarely suffer problems with them... except for one site. This site has been going down, and staying down, to the point that I routinely SSH in to forceably restart the locked-up PHP processes.
I've tried to fix it in the past to not avail. Previously I've migrated the site to a new host with an updated OS, tweakes a great many configuration settings all over the system and site, and very recently I've changed the server setup to match that of other high-traffic WordPress sites I host.
But the lockups have been increasing with frequency to the point where, today, the site would not stay up for more than 30 minutes before refusing connections.
Finally fed up, this is my journey to fix it.
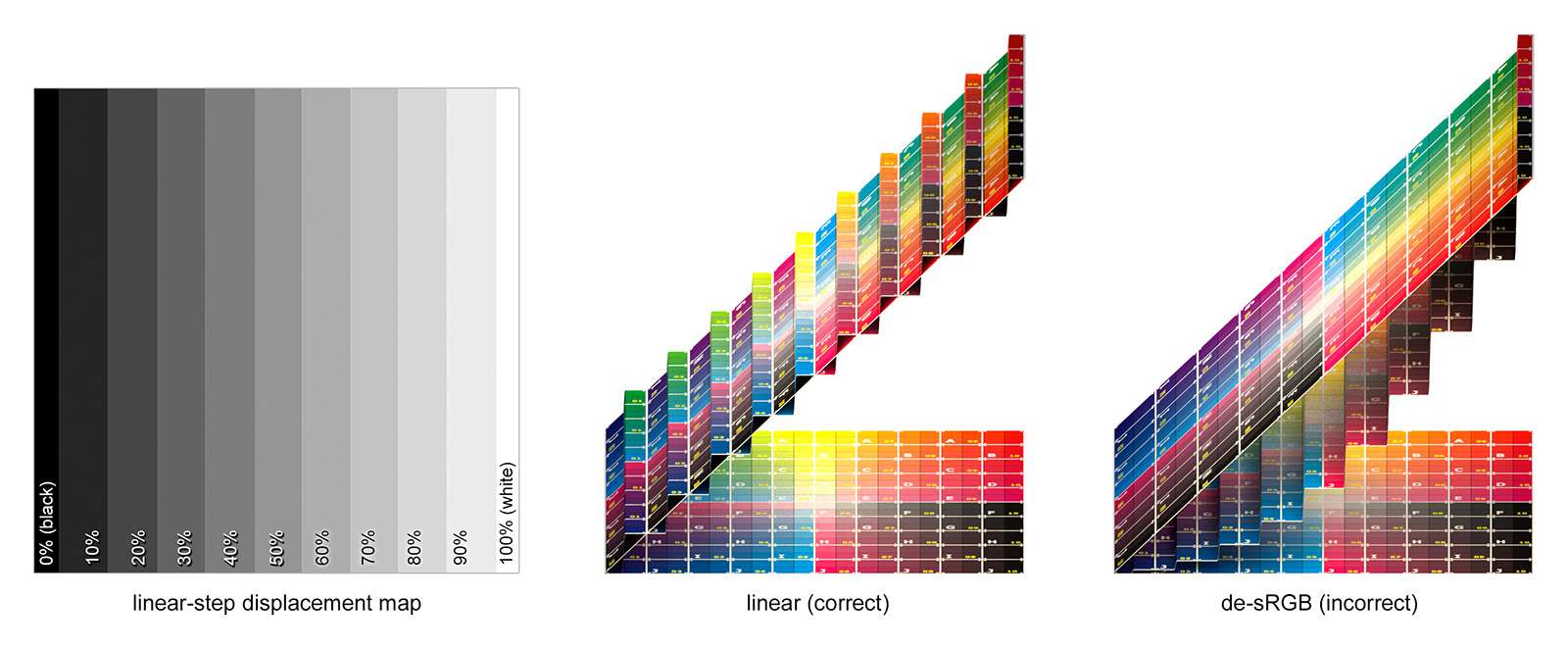
When to NOT Linearize Your Textures
Although most images are non-linear, sometimes you should leave them that way.
Knowing how and when to deal with colour spaces in your textures files is crucial to a realistic rendering workflow.
In short: since monitors are usually non-linear devices, image files are generally stored with the inverse non-linearity baked in (the general example of which is sRGB). Since rendering calculations work in a linear space, you must convert your images back to the linear space before using them otherwise your renders will not be accurate.
While it is key that you linearize your colour textures (e.g. diffuse, specular colour, etc.), you must be very thoughtful of doing the same with your data textures (e.g. displacement, bump, etc.).
For example, lets look at a displacement:
View posts before February 27, 2015