Post Archive
A Complete Shotgun Schema
Reading the "private" schema for all the details.
My site-local Shotgun cache is coming together quite nicely; you can see the progress on GitHub, as well as the ongoing results of my reverse-engineering efforts.
As work progresses, there is a greater and greater need for a through understanding of Shotgun's database schema so that I can replicate its behavior. One example that I'm starting to tackle: when you query an entity or multi_entity field, the entities will return the (required) type and id, but also a name, however, if you query for that name field you will find that it doesn't actually exist:
>>> # Lets grab the pipeline step of any task: >>> sg.find_one('Task', [], ['step']) {'step': {'type': 'Step', 'id': 4, 'name': 'Matchmove'}, 'type': 'Task', 'id': 2} >>> # Notice the name... ^^^^^^ here. >>> # Let's grab that name directly: >>> sg.find_one('Step', [('id', 'is', 4)], ['name', 'code']) {'code': 'Matchmove', 'type': 'Step', 'id': 4} >>> # No 'name' to be found. Huh.
Another example is the description of back-references of many multi_entity fields. E.g. if you set Task.entity to a Shot, that task will end up in Shot.tasks as well.
I have reached out to Shotgun support, and they have confirmed to me that the schema returned by the public API's schema_read (and related) methods would need to be expanded to return the information I need.
There must be another way to get this information, because the Shotgun website works, and it must have it. So lets go digging there...
Static Libraries in a Dynamic World
Creating more honest versions of wrapped APIs.
There is a common pattern when using bindings for C libraries that work against the dynamic language I'm working in: the conceptual packages in the library (which are exposed as header includes, and so provide no extra overhead to use in your code) are actually packages in the binding.
Unless they are flying in the face of good practices, the dynamic language user actually has to work harder to identify a specific function/variable than the static language user would!
The Problem
Let's look at an example Qt program written in C++:
1 2 3 4 5 6 7 8 9 | #include <QApplication> #include <QPushButton> int main(int argc, char *argv[]) { QApplication app(argc, argv); QPushButton hello("Hello world!"); hello.show(); return app.exec(); } |
If we translate directly to Python, we are left with code that feels not only too specific, but puts more of a burden on the programmer than they would have with the static version of the library since they need to know exactly where every object comes from:
1 2 3 4 5 6 7 | import sys from PyQt4 import QtGui app = QtGui.QApplication(sys.argv) hello = QtGui.QPushButton("Hello world!") hello.show() exit(app.exec_()) |
This is something I encounter all the time. For example, in PyQt/PySide, the Adobe Photoshop Lightroom SDK, PyOpenGL, Autodesk's Maya "OpenMaya", PyObjC use of Apple's APIs, etc..
Repairing Python Virtual Environments
When upgrading Python breaks our environment, we can rebuild.
Python virtual environments are a fantastic method of insulating your projects from each other, allowing each project to have different versions of their requirements.
They work (at a very high level) by making a lightweight copy of the system Python, which symlinks back to the real thing whenever necessary. You can then install whatever you want in lib/pythonX.Y/site-packages (e.g. via pip), and you are good to go.
Depending on what provides your source Python, however, upgrading it can break things. For example, I use Homebrew, which (under the hood) stores everything it builds in versioned directories:
$ readlink $(which python) ../Cellar/python/2.7.8_2/bin/python
Whenever there even a minor change to this Python, symlinks back to that versioned directory may not work anymore, which breaks my virtual environments:
$ python dyld: Library not loaded: @executable_path/../.Python Referenced from: /Users/mikeboers/Documents/Flask-Images/venv/bin/python Reason: image not found Trace/BPT trap: 5
There is an easy fix: manually remove the links back to the old Python, and rebuild the virtual environment.
The Evils of Gamifying Git
Your green squares do you little good, and encourage bad behaviour.
Nearly two years ago, GitHub introduced contribution calendars on everyone's profile, which roughly visualize how frequently one has been "contributing" for the past year. Through 2013, mine displayed some interesting patterns and features, many of which scream that they have a story:
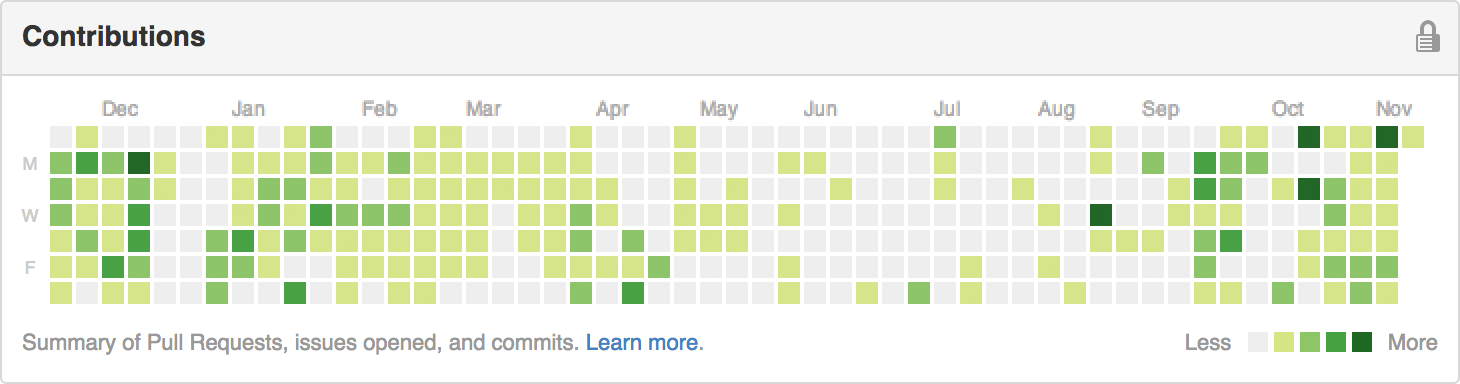
Having used GitHub as the primary code host for multiple full-time jobs, and a few growing open-source projects, I now believe that these calendars introduce, for me, two negative effects that vastly outweigh their benefits.
"Are we getting the same SSL cert?"
A tiny webapp to help answer that question.
A friend had an SSL scare on public WiFi while in a coffee shop today. Her browser was warning her that every SSL certificate was invalid (except for *.google.com). Eventually it stopped, and she overheard others in the coffee shop commenting that their tablet was finally able to connect (it was previously refusing).
I'm not sure, but this could be a man in the middle attack on the WiFi, in which the attacker (somehow) had a valid Google certificate and provided DNS records to point at their own machine.
In this scenario the browser is perfectly content to allow you to connect to this spoofed service. If you are not extremely familiar with SSL certificate authorities, a good way to assert a cert is not a forgery is to compare it to a known-good copy of the certificate. If the signatures match, then you are good to go.
But where can you get a known-good copy?
To answer this question, I quickly make the SSL Cert Fetcher (the source of which is available on GitHub).
Take a look at the certificates for Twitter, Google, and Facebook and see if they match what you are getting. (I'll sit here with my fingers crossed for a while.)
Git Metadata In-Band
Moving configuration and hooks into the tree.
When writing tools for git, or while working on more complex projects, I often need to work with the git configuration or hooks.
Unfortunately (or so I sometimes feel), the configuration and hooks are not stored in the tree (the version controlled part of repo), and must be installed out of band. This easily leads to a non-uniform configuration across clones.
Let's get that information in band!
Render Heatmaps
Are pictures worth 1000 statistics?
Debugging rendering issues can be particularly problematic. Many times, the efficiency of standard debugging procedures (e.g. printing intermediate values, or using a debugger) fall apart at the sheer volume of data they will produce when you are calling them millions of time per frame.
Often, intermediate values can be dumped out via an AOV (i.e. to another image), and inspected as an image. For example, if you were interested in how long various parts of the image are taking to render vs. the others, you could create a heatmap such as:

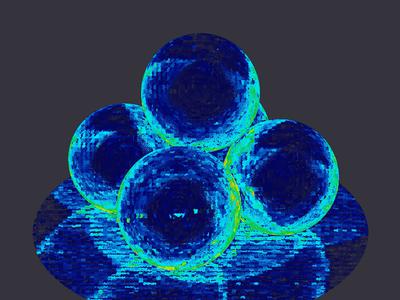
In this particular example, however, there are a few drawbacks:
- RSL does not have any timing functions;
- every shader would need to be modified in order to collect these stats; and
- you generally only receive information from the front-most surface.
I set out to resolve those issues.
The UX of Coupon Codes
How to (try to) avoid confusion and apprehension.
Lately, I have been entering a number of coupon codes on the web, and have found them to be infuriatingly lacking in one respect: the character set used for the codes is not easy to type.
I'm sure we have all questioned at one point if a character in the code was supposed to be a 0 (zero) or O (upper-case letter O), or a 1 (one), I (upper-case letter I), or l (lower-case letter L). Usually you just pick one, and usually you get it wrong the first time.
I find it particularly strange, that Starbucks would go so far as to recognize this problem, but not actually fix it:

As a developer, there are a few increasingly dramatic ways to deal with this.
My Report Card
The second GitHub Data Challenge recently finished, and GitHub just announced the winners.
The first place went to The Open Source Report Card, which generates an English prose summary of your GitHub activity (from January to March 2013), and provides some charts to back it up.
My report card for that period is somewhat eerie (to me):
Mike is a serious Pythonista (one of the top 13% most active Python users) who loves pushing code. Mike is a nine-to-fiver who seems to work best in the mid-afternoon.
[...]
It seems—from their activity streams—that Mike and westernx are probably friends or at least virtual friends. With this in mind, it's worth noting that westernx is less foul mouthed
I would love to see a chart about my tendency to swear in commit messages.
There are no more posts tagged "development".